
Peer Cluster Filtering is an optional feature in Dynamic Benchmarking platforms that uses a group of named accounts as the comparison data set (an account contains the data supplied by a participant and typically represents an organization, facility, company, etc.). Like criteria-based filters, peer cluster filter results are shown in the “aggregate” which means that no individual data points or responses are exposed. Strict data minimums must be met for results to display, which ensures anonymity while still offering a unique way to select a comparison data set. This makes Peer Cluster Filtering a highly valued feature by many of our clients.
CREATING PEER CLUSTERS
There are two ways Peer Clusters can be enabled. Decisions on which option is best will be based on discussions with the customer. All peer cluster setting options are controlled by Dynamic Benchmarking.
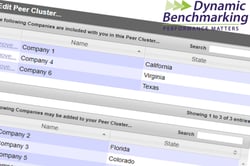
User Created: The setting must be enabled to allow users to create their own peer clusters. To get started, a user select accounts by name to be a part of a peer group, then names and saves the peer group for future use. When activated, the user responses are compared to the responses of the peer group with results only displayed in the aggregated and if minimum data requirements are met. These peer groups are only visible to the users associated with the account that created them. Typically, all accounts are included in the selectable list for peer group creation, however, there is an option for exclusion that an administrator can activate.
Example: A medical practice knows who the top ten highest performing practices are in their area. It creates a peer cluster by selecting those ten practices and uses it as a dynamic filter to compare its performance against that group.
Administrator Created: These are also known as Private Peer Clusters as they are created via the platform administrator and not the users. Similar to user created peer clusters, the administrator selects accounts, names and saves the peer cluster. The peer cluster is only visible to the accounts included in that cluster. Accounts that are not part of the peer cluster will never see it. This is a great way to allow specific peer group comparisons without letting users create their own. There is also an option to hide the names of the accounts included in the private peer cluster for less transparency as needed.
Example: There are established groups of medical practices that like to compare performance against each other. The administrator sets up a private peer cluster for this group of practices. Only the practices in the peer cluster can see and use it as a filter option for comparing their performance.

USING PEER CLUSTERS
Peer Clusters work like any other dynamic filter. Users simply select “Peer Cluster” instead of the available criteria-based filters. They can either create their own, activate one of their own or activate a pre-created private peer cluster, depending on platform settings. Peer cluster filters can also be used in conjunction with criteria-based filters if there are enough accounts in the peer group. This provides for quite dynamic and unique filtering scenarios.
Once a filter is activated (peer cluster or a combination with criteria-based filters), users can see how many accounts match their filter settings and the average number of responses. Filter settings can be named and saved as ‘Filter Favorites” for future use.
About half of our customers actively use Peer Clusters in their studies. They find them useful in comparing their results to other “named” participants for more specific and targeted peer comparisons. It is, of course, an optional feature, as DB is aware that our customers have a variety of privacy requirements but for those who can use it, Peer Clusters is a much valued feature from Dynamic Benchmarking.
