
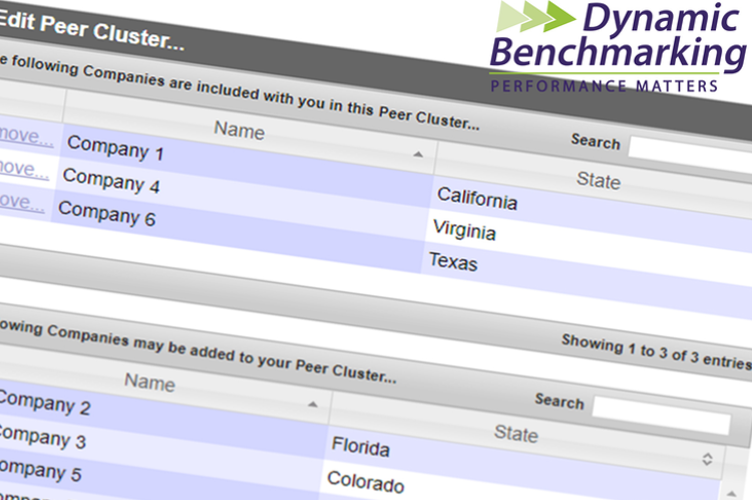
Peer Cluster Filtering is an optional feature in Dynamic Benchmarking platforms that uses a group of named accounts as the comparison data set (an account contains the data supplied by a participant and typically represents an organization, facility, company, etc.). Like criteria-based filters, peer cluster filter results are shown in the “aggregate” which means that no individual data points or responses are exposed. Strict data minimums must be met for results to display, which ensures anonymity while still offering a unique way to select a comparison data set. This makes Peer Cluster Filtering a highly valued feature by many of our clients.




